Abstract
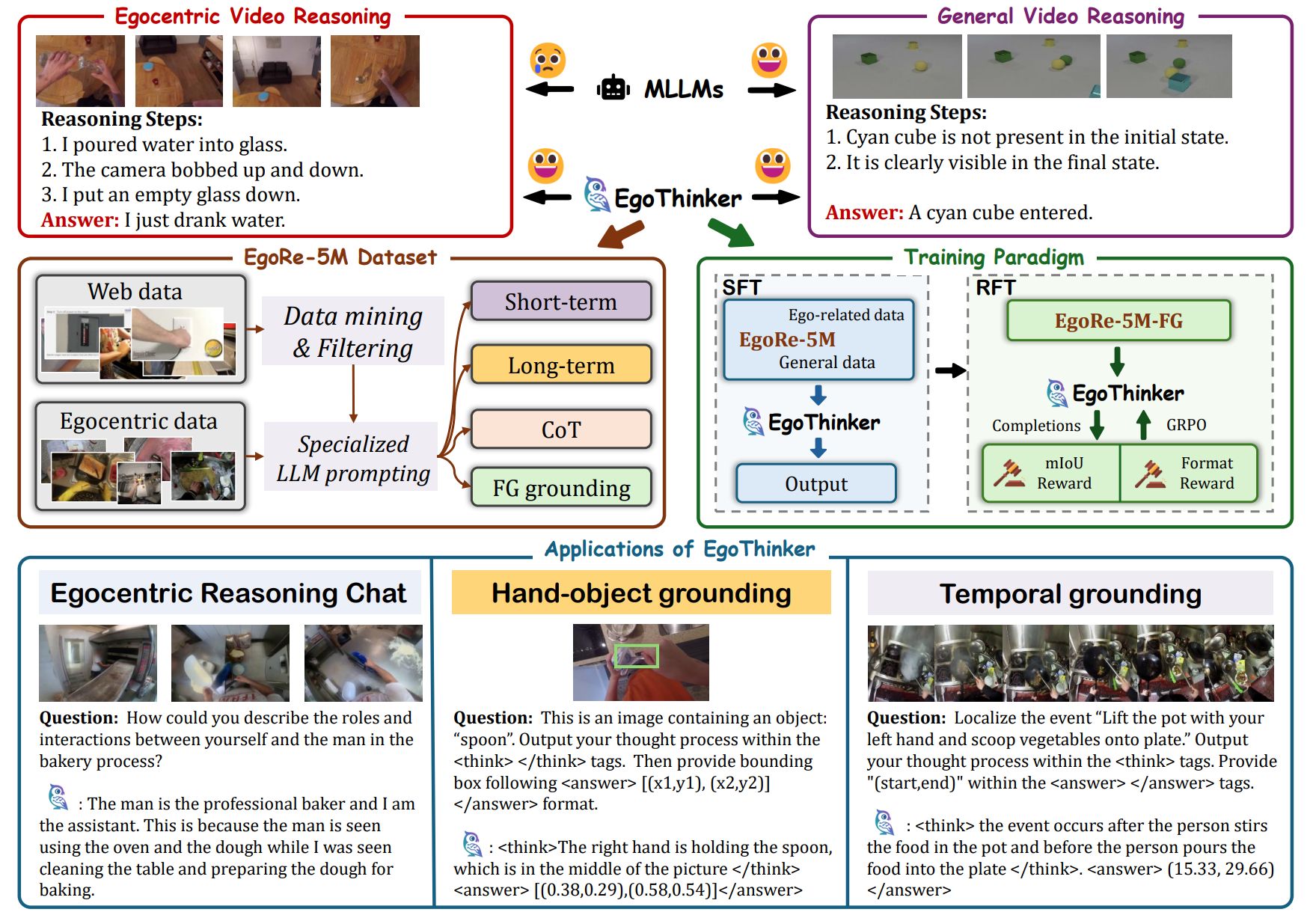
Egocentric video reasoning centers on an unobservable agent behind the camera who dynamically shapes the environment, requiring inference of hidden intentions and recognition of fine-grained interactions. This core challenge limits current multimodal large language models (MLLMs), which excel at visible event reasoning but lack embodied, first-person understanding. To bridge this gap, we introduce EgoThinker, a novel framework that endows MLLMs with robust egocentric reasoning capabilities through spatio-temporal chain-of-thought supervision and a two-stage learning curriculum. First, we introduce EgoRe-5M, a large-scale egocentric QA dataset constructed from 13M diverse egocentric video clips. This dataset features multi-minute segments annotated with detailed CoT rationales and dense hand–object grounding. Second, we employ SFT on EgoRe-5M to instill reasoning skills, followed by reinforcement fine-tuning (RFT) to further enhance spatio-temporal localization. Experimental results show that EgoThinker outperforms existing methods across multiple egocentric benchmarks, while achieving substantial improvements in fine-grained spatio-temporal localization tasks.
Overview
Unlike general video reasoning, egocentric video reasoning poses unique challenges because it must infer an unobservable camera wearer’s interactions and intentions. EgoThinker addresses this by curating EgoRe-5M, a large-scale egocentric reasoning dataset, and applying a two-stage supervised and reinforcement fine-tuning paradigm. This design empowers robust egocentric reasoning chat, hand–object grounding, and temporal grounding, making EgoThinker a promising foundation for wearable assistants and embodied AI.
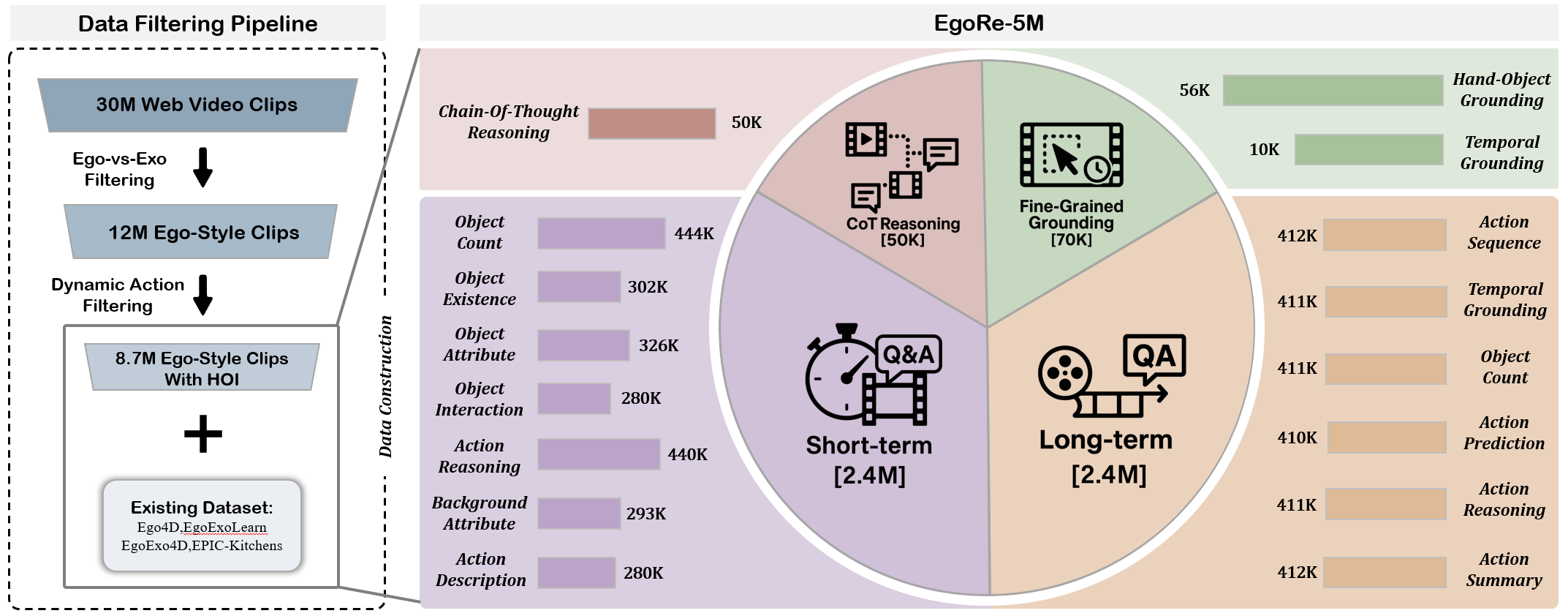
Instruction Tuning Data
(a) To overcome this scale bottleneck in egocentric data, we develop a multi-stage filtering pipeline to mine high-quality egocentric clips from web-sourced videos, through the pipeline we get 8.7M high-quality egocentric clips, each containing rich, dynamic interactions suitable for downstream QA annotation and we combine them with existing egocentric dataset to form a collection of 13M egocentric video clips in total. (b) Based on the large-scale video clips, we build EgoRe-5M, an automatically generated QA corpus containing short-term perception, long-term causal reasoning, chain-of-thought rationales, and fine-grained grounding.